Parsing PDFs with AI - How I Built a Zero-Trust, Client-Only PDF Parser in the Browser
Here's how I developed a fully client-side PDF parser that converts documents into structured JSON using a local LLM - all offline, without the data leaving the browser. An interesting future approach for financial, legal and privacy applications.

It all began with a customer enquiry that had a clear requirement for a prototype: To convert documents into structured JSON - without compromising on data privacy.
The customer operates in a field where sensitive data is the norm - contracts, financial reports, insurance documents - and they needed a way to gain structured insights from these documents.
But there was a catch: no document-related data was allowed to leave the user’s browser.
Trust, data ownership and local processing are non-negotiable.
So I set out to develop a customer-only showcase to prove that it was possible to extract documents directly in the browser and transform them into JSON.
The result is the Browser Document Parsing Showcase: A hands-on demo showing how we can load a document like a PDF, extract its text content, and semantically transform it into a pre-defined JSON structure (Zod) - powered by local JavaScript and centrally driven by LLM (WebLLM) support for structure and meaning extraction.
Hypothesis
Let's start with the initial hypothesis 👇
If we can combine local document parsing in the browser with LLM-powered transformation, we can build a zero-trust, client-side prototype that provides structured, meaningful structured data from financial and insurance PDFs - without ever leaking private data to a server.
Overview
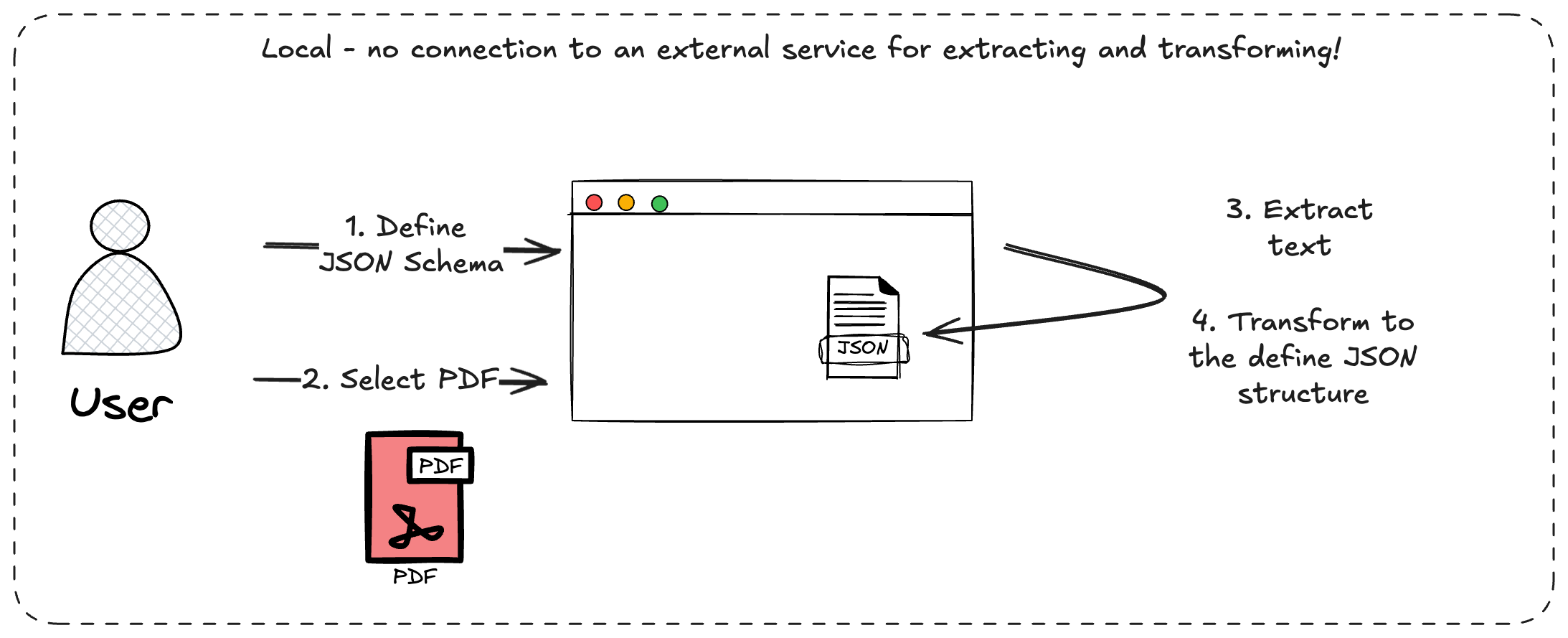
- The user pre-defines a JSON schema (based on Zod) or select a pre-defined schema.
- The user selects a pdf which should be transformed to this pre-defined JSON structure and give it to the browser.
- The app extract the text from the pdf via pdfjs-dist
- The extracted text will be transformed by a selected LLM (WebLLM) in the Browser to the predefined JSON structure.
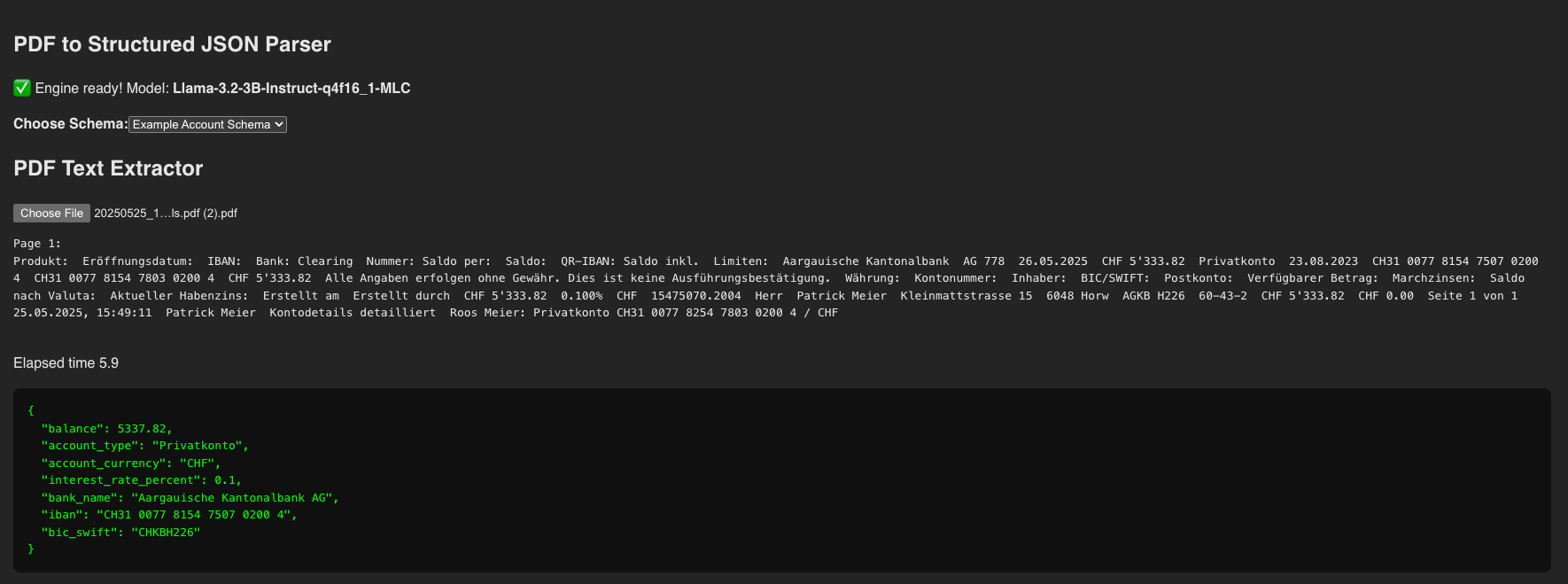
Tech Deep Dive
Let's take a look under the hood.
LLM as WebAssembly
The LLM (e.g., Llama, Phi-3) is pre-compiled to WebAssembly and loaded into the browser once (via WebLLM).
On first load:
- 0a. It is downloaded and stored in IndexedDB for caching.
- 0b. On subsequent visits, it's retrieved directly from the cache.
Execution with WebGPU and WASM
Inside the Web Worker, the MLC Engine:
- Executes GPU kernels using WebGPU (via WGSL).
- Runs non-kernel logic using WebAssembly (WASM).
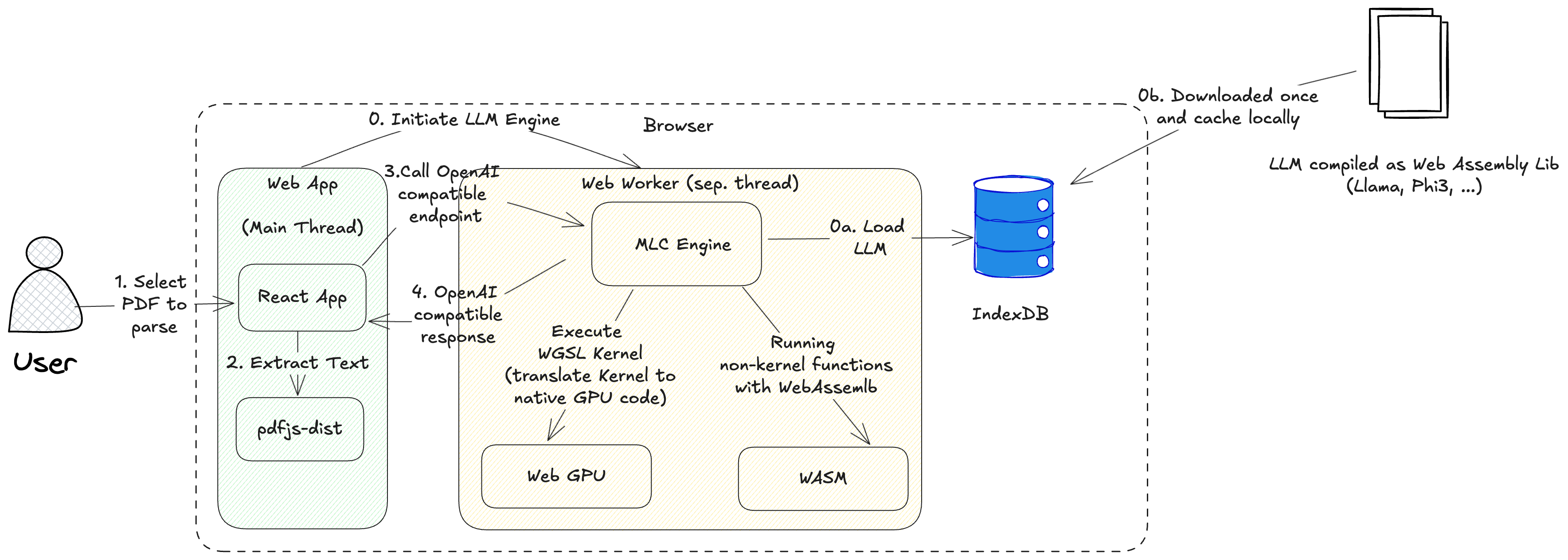
This diagram shows how our fully client-side system converts a PDF document using a local LLM (e.g. Llama or Phi-3) into structured data that is compiled in WebAssembly and executed directly in your browser - no server, no cloud, 100% private.
Step-by-step Flow
- The user selects a PDF file for parsing
The process begins when a user places a PDF file in the browser. - Extract text using pdfjs-dist
A React-based frontend (running in the main thread) uses the pdfjs-dist library to extract the raw text from the PDF file. - Call OpenAI-compatible endpoint
The extracted text is passed to a web worker that wraps an OpenAI-compatible interface with the MLC engine. This keeps heavy computations away from the main thread to improve performance. - Receive OpenAI-compatible response
The local LLM processes the text and responds with a structured interpretation - just as you would expect from OpenAI, but offline and private.
This hybrid execution model ensures that even complex models can be executed efficiently in the browser.
Why Client-Side Document Parsing Matters
Traditional document extraction solutions rely on uploading documents to a server or third-party service - which is probably not an option if data privacy is particular important.
With the advances in browser APIs, WASM and small local LLMs, we can now:
- Parse and analyse documents in real time
- Maintain full control over user data
- Encrypt structured results and store them securely in the cloud
- Provide secure, private insights into documents
And all this without sending a single unencrypted byte to the cloud.
Conclusion
The Browser Document Parsing Showcase demonstrates that it is perfectly possible to parse, analyse and structure documents directly in the browser - all while maintaining complete user privacy.
Combined with client-side encryption and secure cloud storage, this approach provides a solid foundation for developing trustworthy applications in areas such as insuretech, legaltech, edtech or finance.
Current restrictions
This solution depends on the WebGPU API, which is not yet enabled by default in browsers such as Safari and Firefox - users must enable it manually via feature flags.
In addition, the model downloads and the computing effort are resource-intensive, so that this solution is currently not suitable for most mobile devices. Therefore, its use is largely limited to high-performance desktop environments, especially those based on Chromium.
These limitations mean that the approach is not yet suitable for widespread use in production.
A look into the future
In the future, I expect browsers to be equipped with integrated LLMs and standardised APIs for local access. This would make the private understanding of documents on the device not only possible, but also practical — both on the desktop and on mobile platforms.
Prototype Source
Interested in building on top of it? Contributions and feedback are welcome!



Comments ()