What is a monorepo and when should it be used?
In contrast to polyrepo, there's the monorepo technique: a monorepo is a single repository for an entire organisation that contains several different projects with clearly defined relationships.
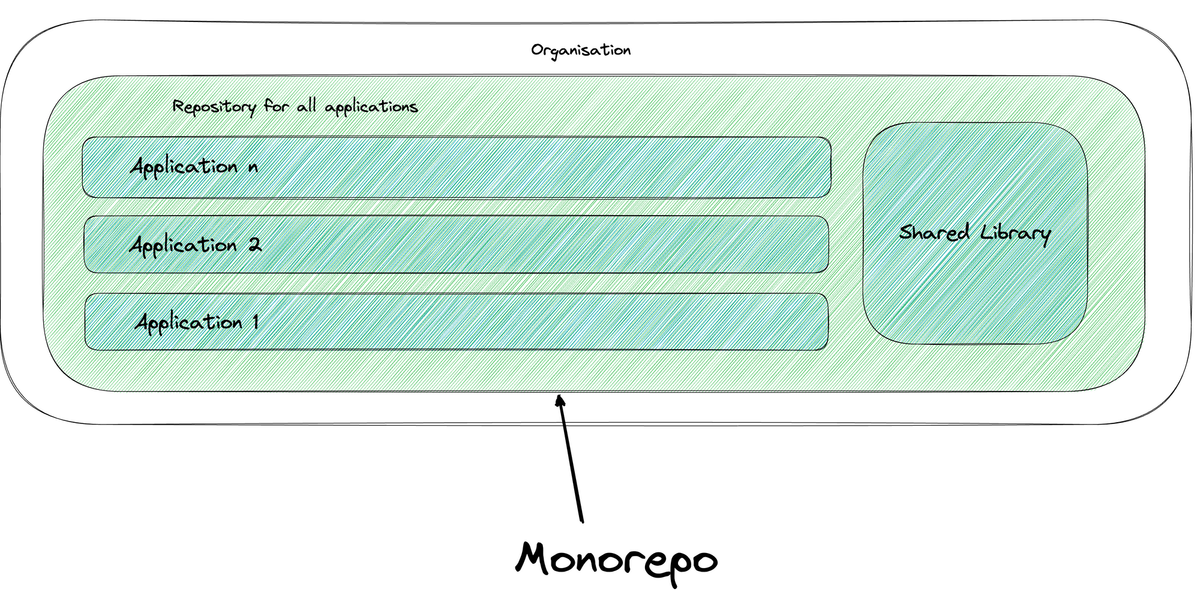
Table of contents
Monorepo vs. Polyrepo
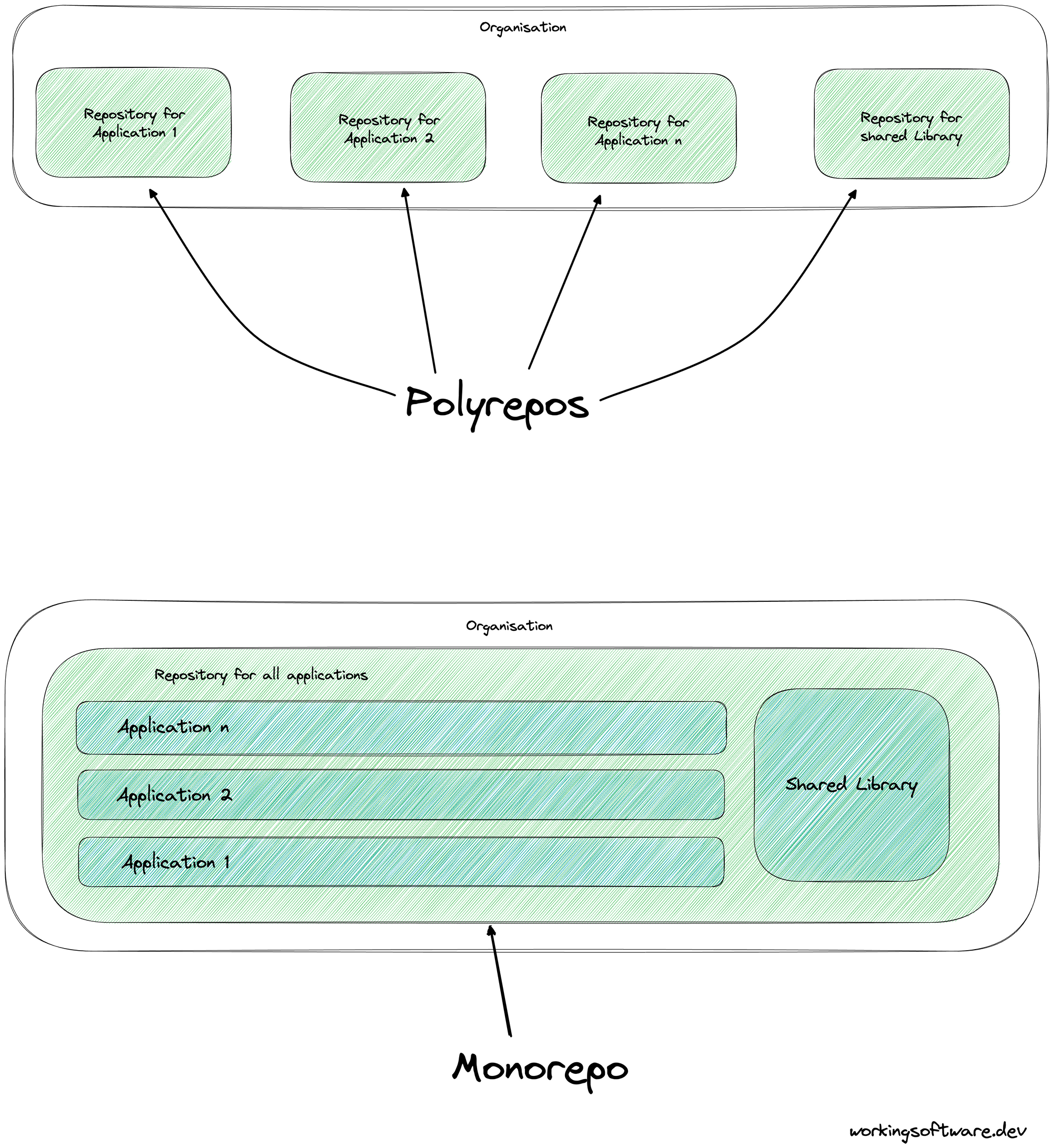
For a long time, the de facto standard for structuring source code in Git repositories was the polyrepo approach.
Polyrepo means that there's a separate repository for each team, application, or project. Typically, each repository has a single build artefact and a simple build pipeline.
In contrast to polyrepo, there's the monorepo technique: a monorepo is a single repository for an entire organisation that contains several different projects with clearly defined relationships.
The following figure shows the difference between these two techniques when dealing with Git:
Why are monorepos good?
With the monorepo approach across all projects you're able to:
💡 Local and distributed computation caching.
The ability to store and reuse files and process output from build and deployment tasks.
Whether on the same machine or remotely across different environments, you'll never build or test the same thing twice.
💡 Workspace Analysis
You've a single source of truth for all projects in one repository. So you can analyse the entire dependency graph easily.
💡 Easy code sharing
Each project can share its code with other projects without any additional configuration overhead.
💡 Local and distributed task orchestration
You can run different time-consuming tasks in parallel. So it's also possible to delegate some tasks to different distributed build agents that can be easily orchestrated.
💡 Identify affected projects and packages
When you change a common source code, you can directly see which projects and packages are affected.
💡 Consistent tooling
A monorepo means that you've the same build tooling and build logic for all projects.
Resources
