Hands-on: How a serverless architecture can work
This is a sneak peek of my learning project that shows how a serverless architecture can work with React, Supabase and Azure Functions.
Here are the results of 8 hours work:
- Web App: https://frontendstats.workingsoftware.dev/
- Twitter Bot: https://twitter.com/frontendstats
Table of contents
- What's the serverless side project about?
- High Level Building Blocks
- Supabase Components
- Web Frontend
- Azure Function
- Conclusion
What's the serverless side project about?
In order to learn React and get my hands dirty with Supabase, I decided to implement a small serverless side project.
Serverless computing is a method of providing backend services on a per-use basis. A serverless provider allows users to write and deploy code without having to worry about the underlying infrastructure. An organisation using backend services from a serverless provider is charged based on its computing power and doesn't have to reserve and pay for a fixed amount of bandwidth or number of servers because the service scales automatically.
The side project is a Frontend Stats Web App that continuously provides GitHub stats about the most popular frontend frameworks like Vue, React, Angular and so on.
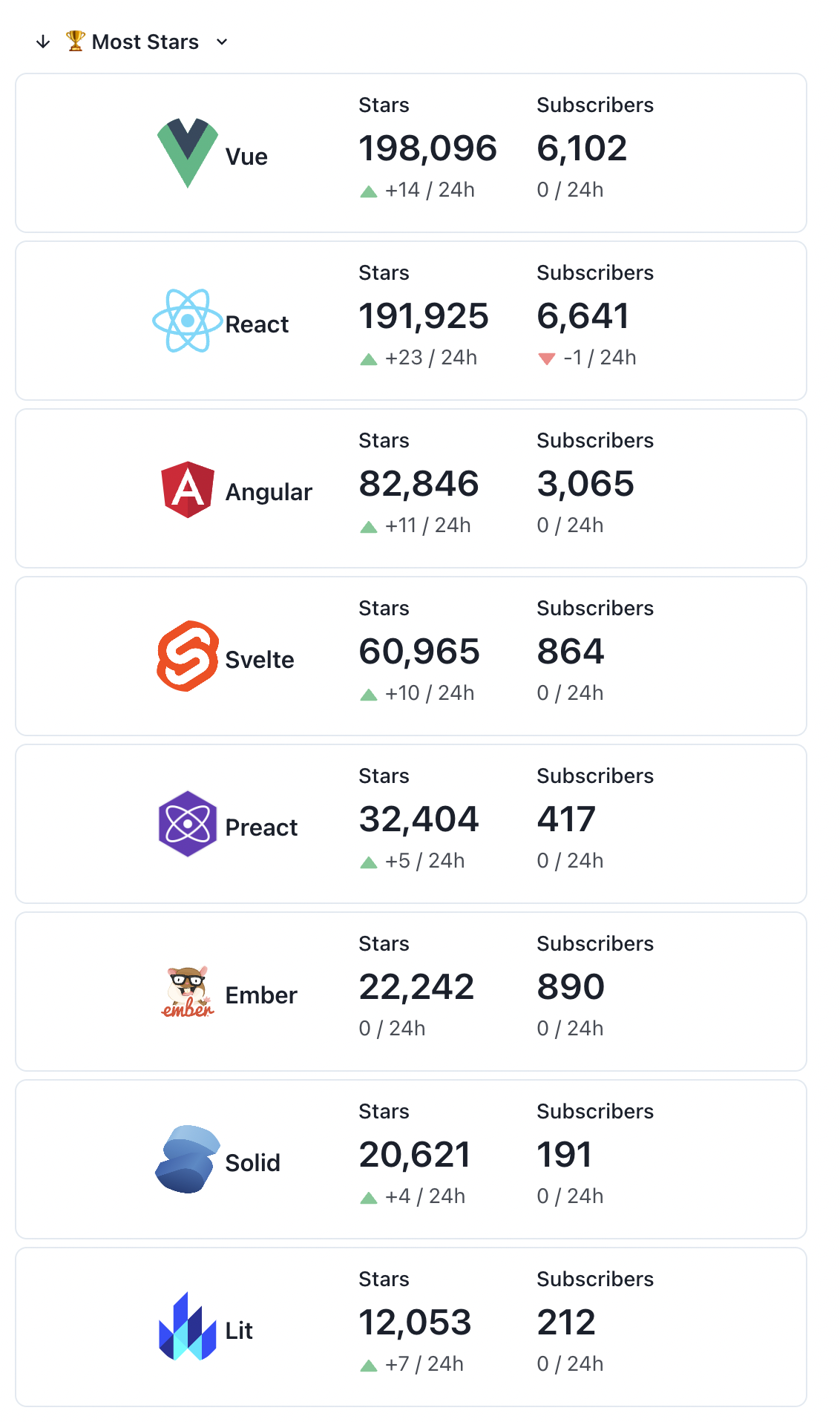
📢 GitHub Stats: #Vue: ⭐ 198,096 👁️ 6,102 #React: ⭐ 191,914 👁️ 6,641 #Angular: ⭐ 82,840 👁️ 3,065 #Svelte: ⭐ 60,961 👁️ 864 #Preact: ⭐ 32,397 👁️ 417 #Ember: ⭐ 22,242 👁️ 890 #Solid: ⭐ 20,618 👁️ 191 #Lit: ⭐ 12,052 👁️ 212
— Frontend Framework Stats 🔥 (@frontendstats) July 26, 2022
The goals of the side project
The main motivation for this project was learning goals:
- To learn the basics of React
- To gain experience with serverless architectures and to get my hands dirty with Supabase and Azure Functions
Project goals
In addition to my learning objectives, I'd like to achieve the following goal with the side project:
Requirements
This means the following functionality:
- Comparison of the currently most popular front-end frameworks in terms of GitHub Stars and Subscribers received
- The comparison data should be viewable via a web frontend and continuously published via Twitter Bot.

So my app should answer the following questions:
- Which front-end framework has the most GitHub stars or subscribers?
- Which frontend framework has received the most stars or subscribers in the last 24 hours?
Non-Functional Requirements
- The statistics should be up to date at least every hour.
- The app should be open and extensible to other technologies. It should take less than 15 minutes to incorporate a new framework.
- The project should have no operating costs.
- The project should create a learning effect regarding the React, Supabase as well as Postgres
- The workload for the project shouldn't exceed 8 hours.
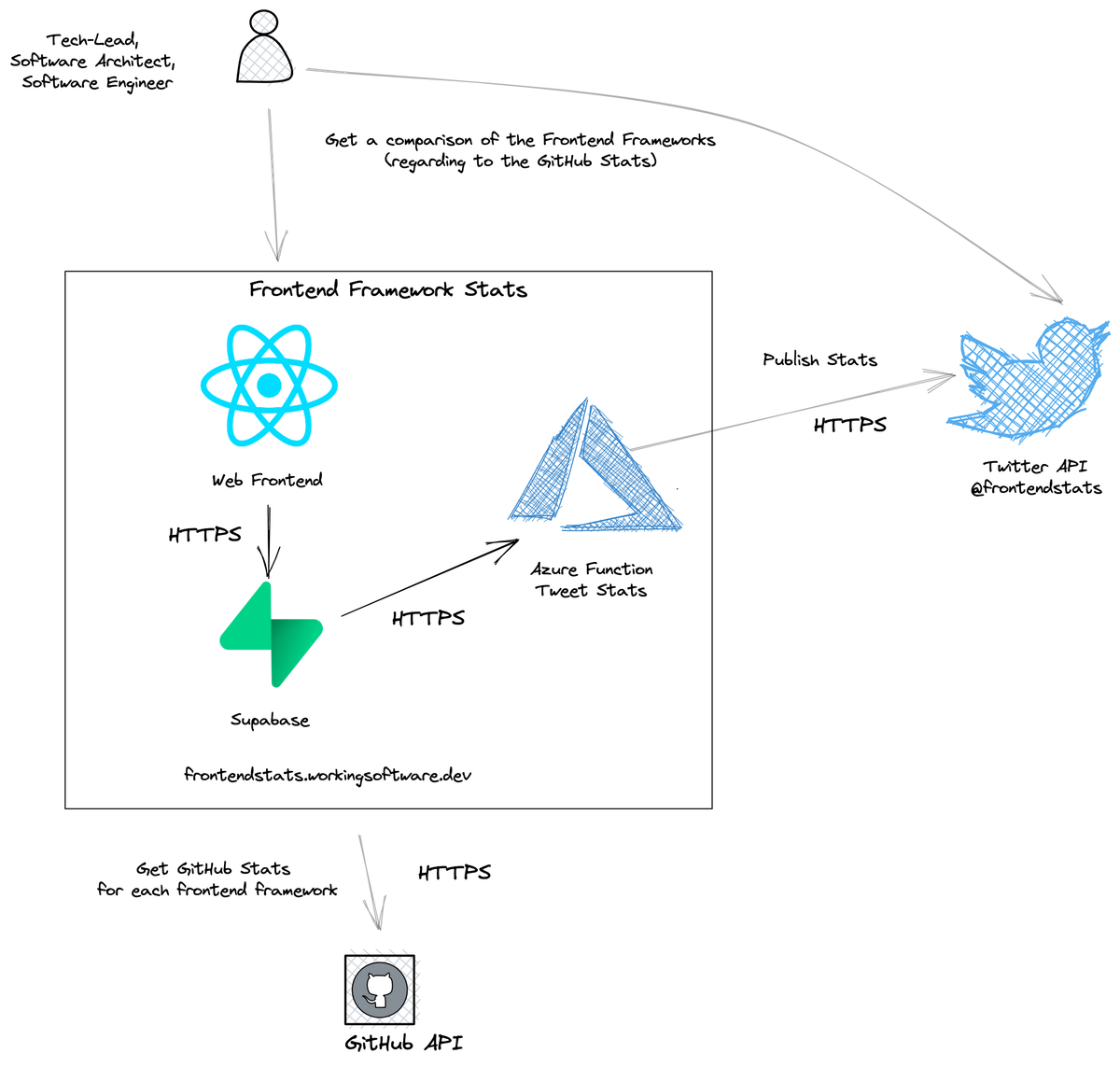
System context
The following figure shows the system context of my small side-project:
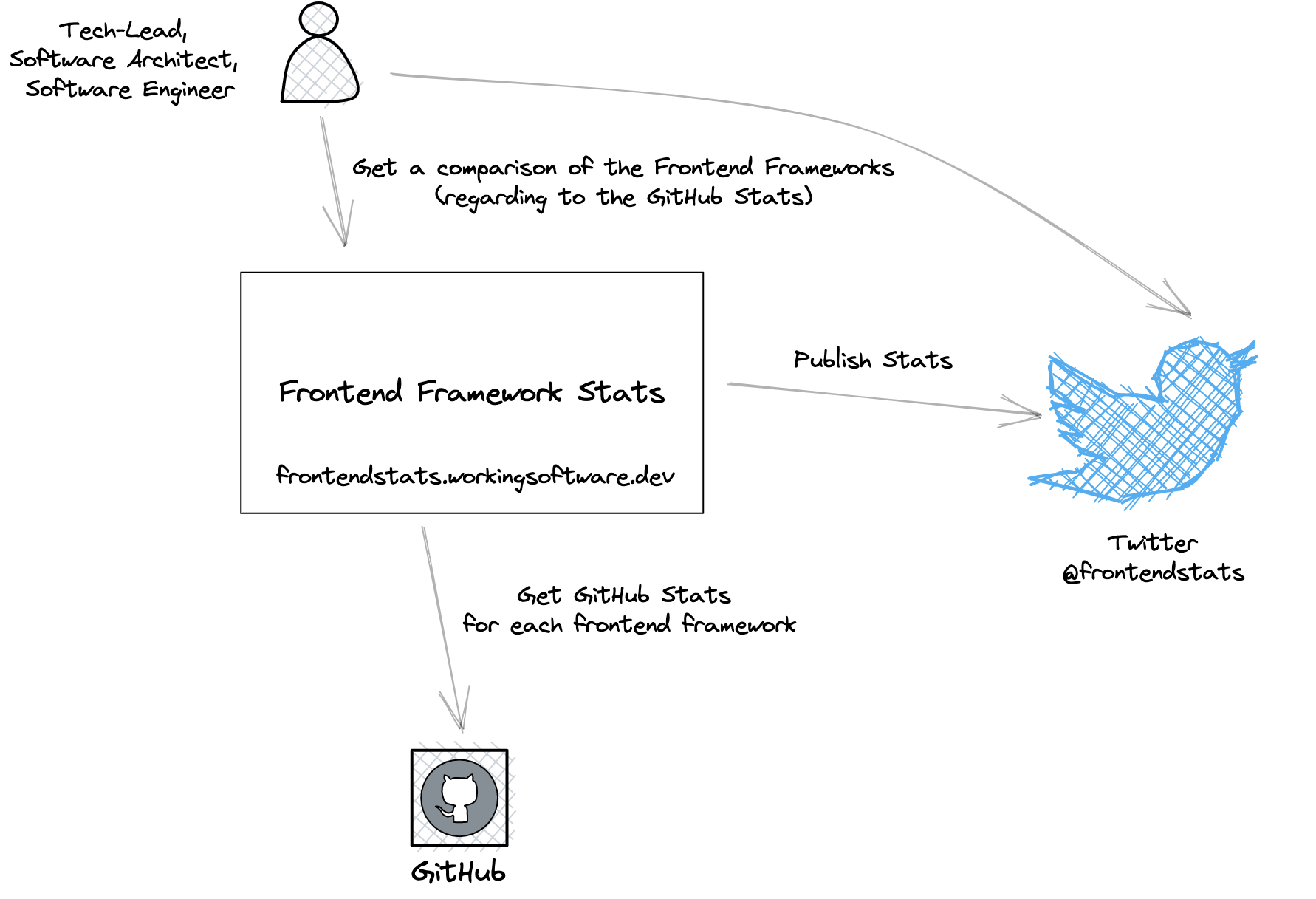
The Frontend Framework Stats system is used by IT people like tech leads, software architects and/or software engineers.
They want a comparison of the most popular frameworks in terms of GitHub stats, like GitHub Stars and GitHub Subscribers. They can view the stats directly in the web frontend or via the Frontend Framework Stats Twitter account, which is fed by the system.
Frontend Framework Stats gets the GitHub statistics directly from the GitHub API.
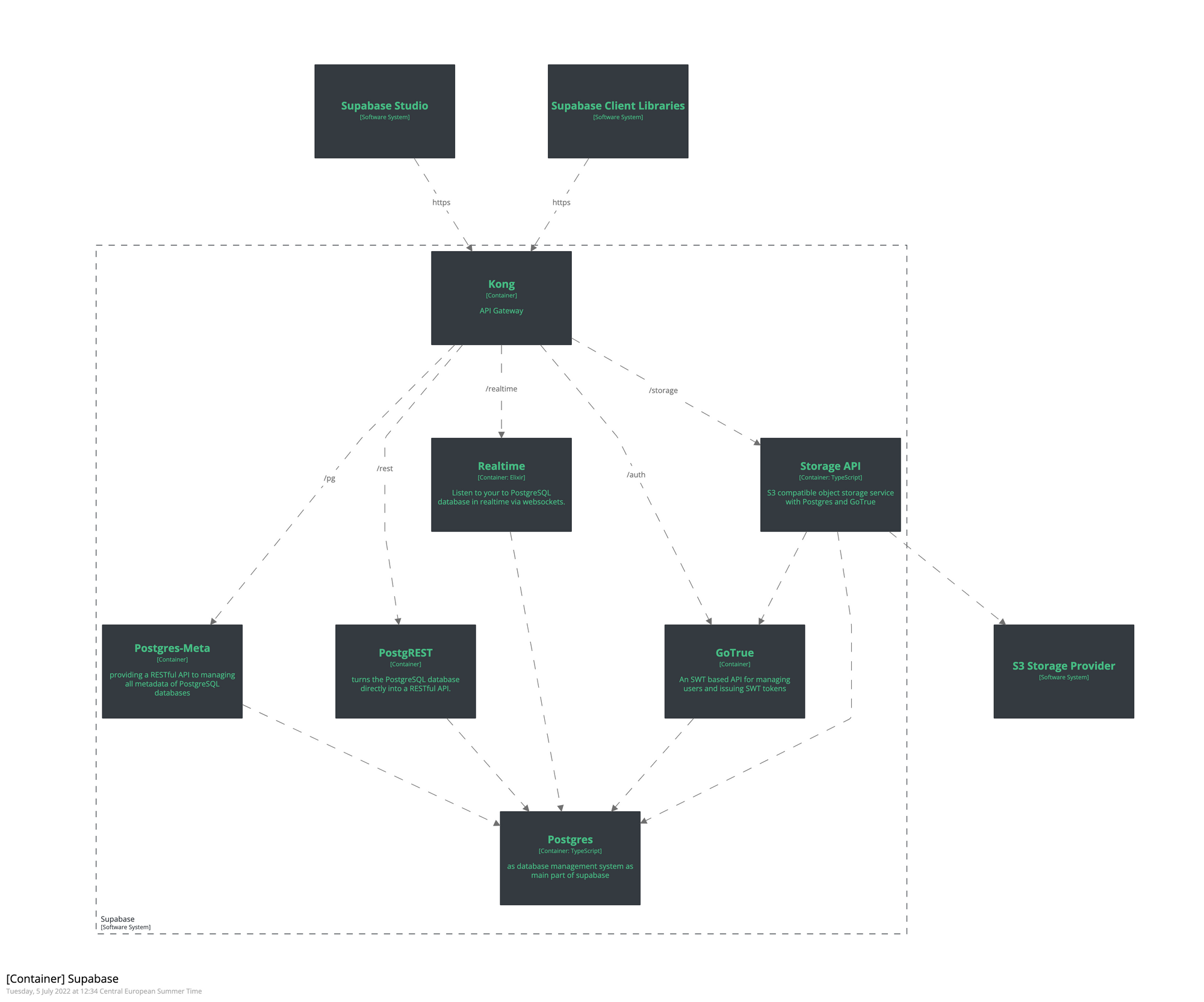
High Level Building Blocks
The following figure shows you the technical building blocks of my side project:
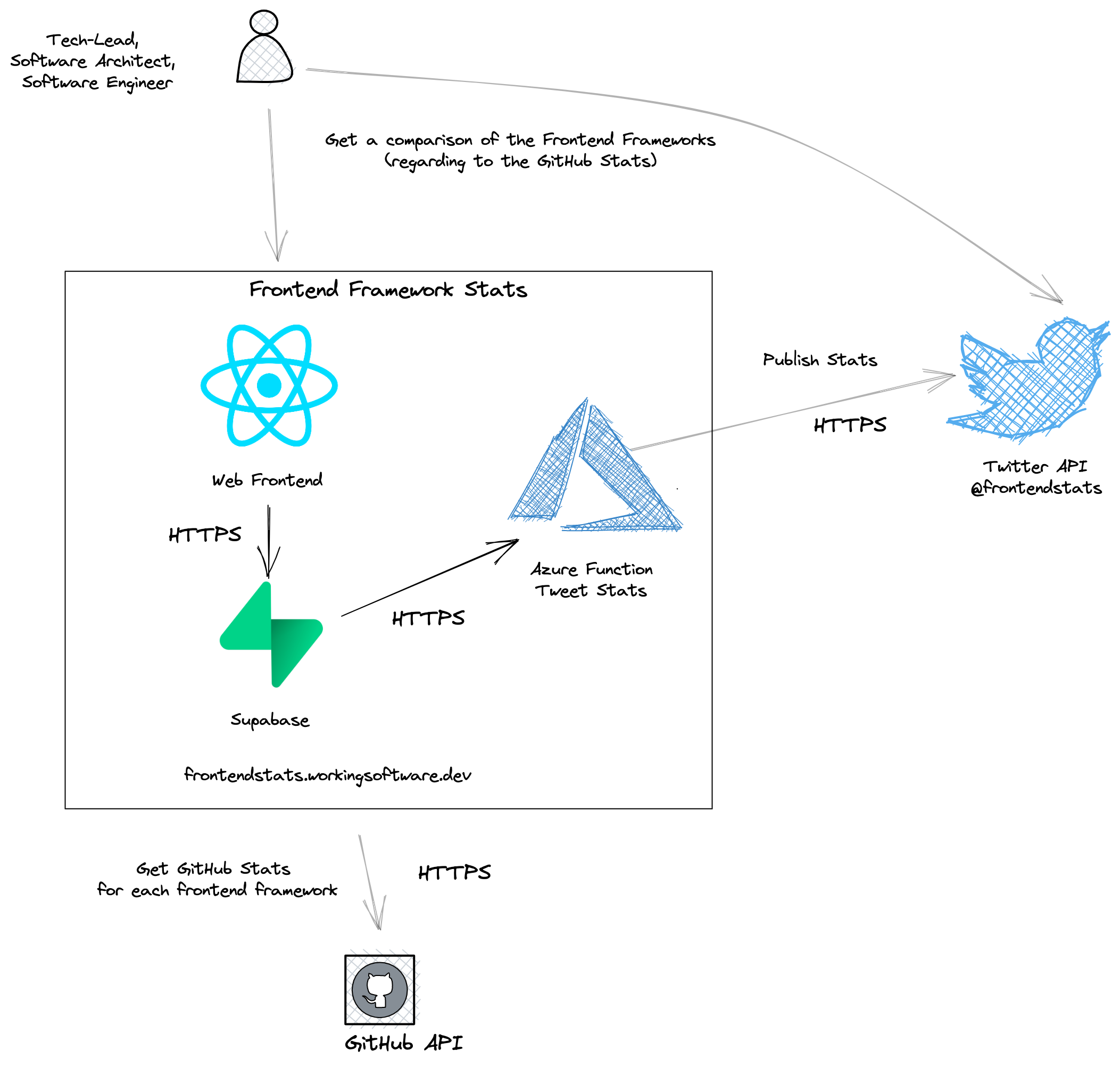
Web Frontend
The web frontend is a single page application based on React and Chakra-UI.
With Chakra-UI I've clean layout elements and UI controls like the Stat with indicator control. This way I can display the frontend stats.
Supabase
Supabase provides me with a backend as a service based on a PostgreSQL database and PostgREST.
GitHub API
Via the GitHub API I get the statistics about the repositories (e.g. Stars and Subscribers) from the different frontend frameworks.
Azure Function
Using Azure Function, I continuously publish frontend stats as tweets via the Twitter API.
Why not use the Edge Functions in Supabase?
Supabase also offers Edge Functions, that are similar to Azure Functions. The current runtime of Edge Functions is Deno. Unfortunately, the Twitter API client for Node used, Twit, isn't currently compatible with Deno.
Therefore, I decided to use Azure Functions as an alternative.
Twitter API
On Twitter, I've the account @frontendstats. With this account I publish the statistics tweets via Twitter API.
An insight into the use of Supabase Components
The following figure shows you an approach to use the Supabase components.
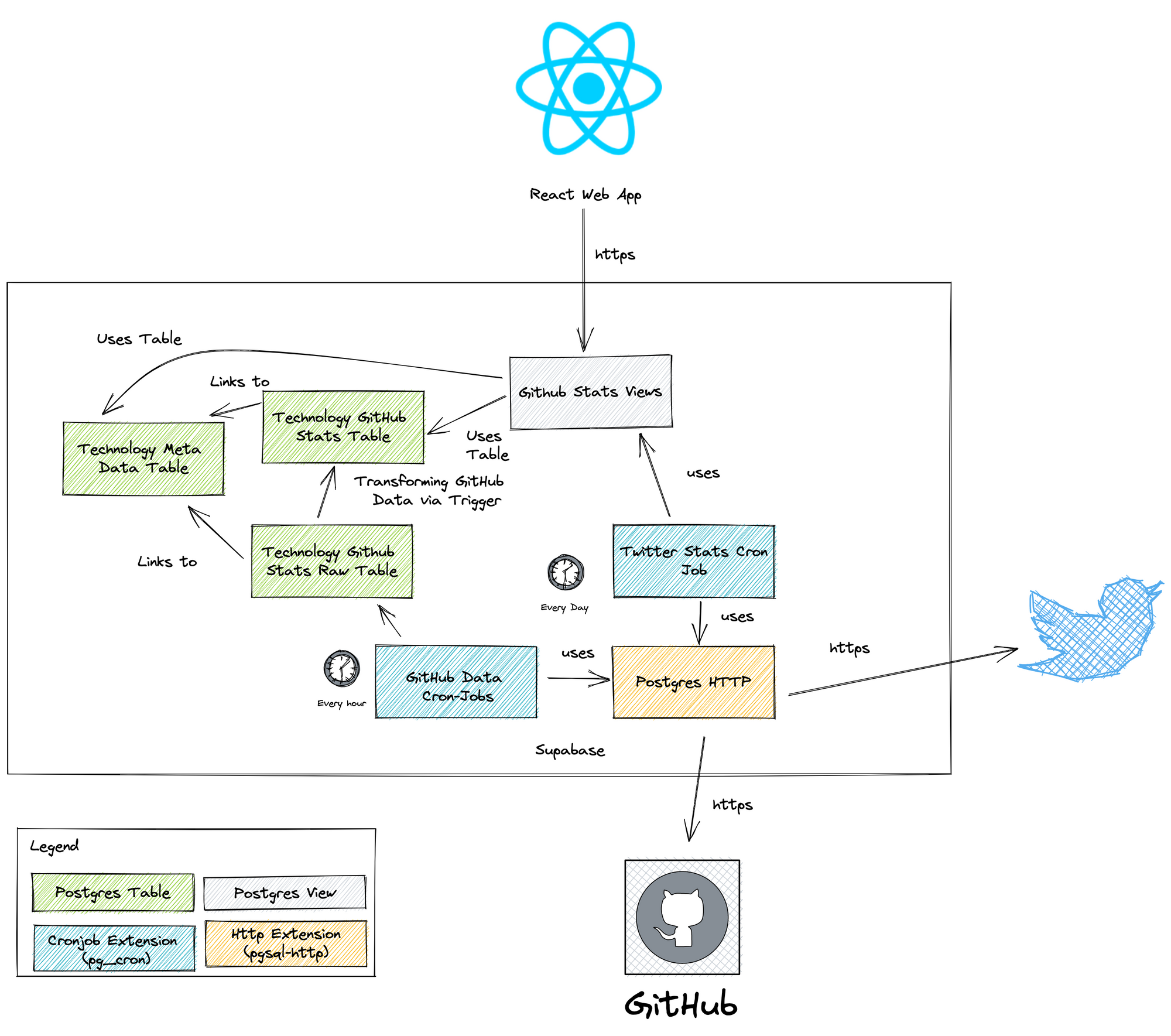
Postgres tables
I've created the following PostgreSQL tables:
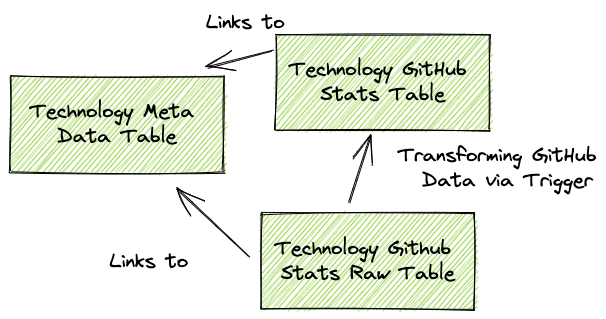
Technology Meta Data Table
The technology table contains all meta information about the frontend framework such as the display name and the link to the logo.
Technology Github Stats
The Technology GitHub Statistics table contains all relevant GitHub statistics about the respective frontend framework, such as GitHub Stars and Subscribers, as well as the change in the last 24h.
Technology GitHub Stats Raw
This table contains the raw data from each regular GitHub API call via the Postgres http extension. When an entry is made into this table, a trigger is fired to convert the json data into the Technology GitHub Stats structured table.
Postgres Cronjobs
Via Supabase Database Extensions there's the possibility to activate the Postgres Cronjobs extension (PG_CRON).
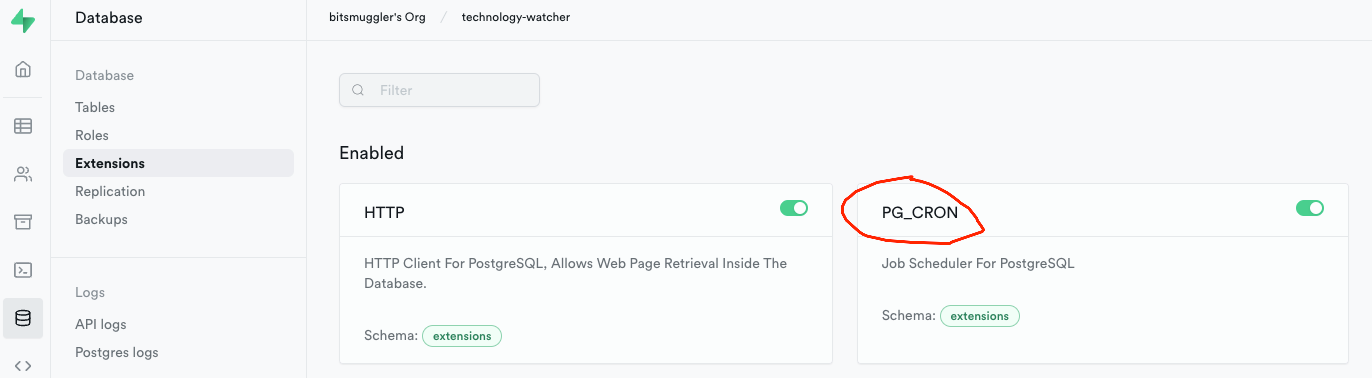
This extension allows me to define cronjobs that are run periodically by Supabase or the underlying PostgreSQL database.
 citusdata
citusdataGitHub Data Cronjobs: Fetching GitHub repository stats
For each technology or framework, I created a cronjob that fetches the latest GitHub stats from the repository. The fetch works via the Postgres HTTP extensions, which can also be enabled via the Supabase extensions.
Such a cronjob definition and the HTTP work as follows:
select
cron.schedule(
'github-angular-metrics-every-day',
'0 * * * *', -- every hour
$$
INSERT INTO technology_github_metrics_raw (data, technology_id)
SELECT cast(github_api.content as json), 1
FROM http((
'GET',
'https://api.github.com/repos/angular/angular', -- 'Fetch repository stats from Angular
ARRAY[http_header('Authorization','token <<GITHUB TOKEN>>')]
)::http_request) as github_api
$$
);Twitter Stats Cronjob: Tweet the latest frontend framework stats via Cronjob and Azure Function
To tweet the latest frontend stats, I also created a cronjob for it. This cronjob calls the Azure Function associated with the specific frontend stats Twitter account.
select
cron.schedule(
'twitter-github-stats-daily',
'0 11 * * *', -- Every day at 11am
$$
SELECT status FROM http_post('<<Link to the Azure Function>>', (select json_data::varchar from github_daily_stats_as_json), 'application/json') -- using a separate view to get the data in json format
$$
);In the cron job I use a special Postgres view to get the data I need in json format.
The cronjob uses a separate view that provides the relevant data in json format that can be sent to the Azure Function.
CREATE OR REPLACE VIEW github_daily_stats_as_json
AS
SELECT json_agg(daily_stats.*)::jsonb AS json_data
FROM ( SELECT distinct on(stats.technology_id) technology_id,
technology.display_name,
stats.stargazers_count,
stats.watchers_count,
technology.logo_url,
stats.technology_id,
stats.stargazers_change_24h,
stats.watchers_change_24h
FROM technology_github_metrics as stats
INNER JOIN technology on technology.id = stats.technology_id ORDER BY stats.technology_id ASC, stats.updated_at DESC) AS daily_stats;The Web Frontend
The React app from frontendstats.workingsoftware.dev is simple.
It's just an App.js that uses Chakra-UI to display stats and supabase-js to retrieve the latest frontend framework stats.
The web frontend is hosted on Vercel and continuously deployed on GitHub.
Retrieving Data from Supabase via supabase-js
I've created a seperate via witch the needed attributes which are displayed on the frontend.
Fetching data via supabase-js is really simple as the following code-snippet shows:
const { data } = await supabase
.from('github_view')
.select(`technology_id, display_name, logo_url, stargazers_count, watchers_count, stargazers_change_24h, watchers_change_24h`);The Azure Function
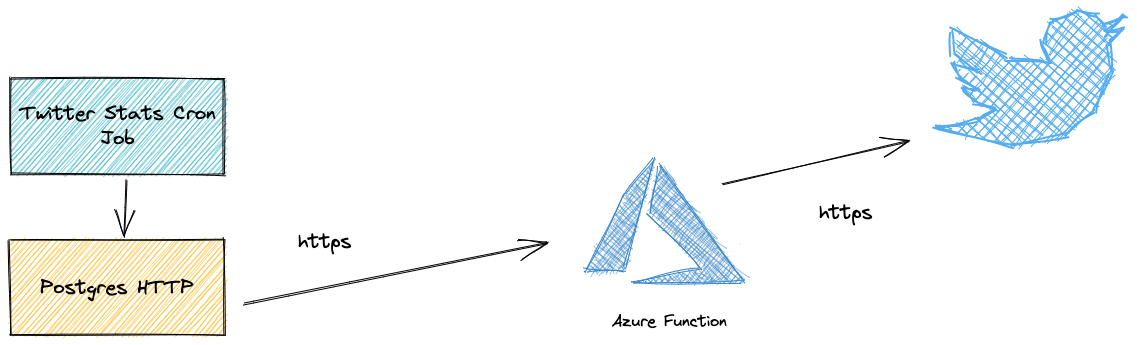
The Azure Function provides a HTTP POST endpoint for the cronjob in Supabase (see above) to retrieve daily frontend statistics. With the GitHub stats as JSON formatted data, the function can create the content for the tweets and post the tweets via the Twitter SDK (Twit).
const tweetGitHubSumStats = () => {
let text = '📢 GitHub Stats: \n';
// Hint: 'data' contains the content of the request body which I get from the Azure Function
data.sort((a, b) => a.stargazers_count > b.stargazers_count ? -1 : 1)
.forEach((framework) => {
text += `#${framework.display_name}: ⭐ ${framework.stargazers_count.toLocaleString()} 👁️ ${framework.watchers_count.toLocaleString()} \n`;
});
tweet(text);
};
Twit handles the entire authentication process for me and provides a simple interface for publishing tweets.
Probably publishing tweets via Postgres HTTP extension would also work, but IMHO this approach is easy to understand and I get help from 3rd party frameworks like Twit. Also, Azure Functions are easily testable.
Conclusion
It's impressive how time to market can be shortened with a serverless technology stack like this:
- I was able to build the front-end statistic app in less than 8 hours.
- With this serverless setup, I've no operational costs.
But there are drawbacks as well:
- Most of the logic is in the database, so it's hard to change it in production.
- The code in the database is IMHO not well testable.
The non-functional requirements drive the architecture and technology stack. Be aware of what architecture style and technology you're using. It depends on the context which approach fits best.



Comments ()